double precision Pd

|
At the time of this writing, 2011, Pure Data still works with
single precision floating point format as it's numeric datatype. With
double precision, some issues could be solved, like indexing of large
audiobuffers. But at what cost? Obviously, double
precision numbers consume double memory. But is double precision also
slower? Is it possible at all to have Pd work at double precision?
|
In order to test performance and evaluate pros and cons, a double
precision Pd must first be built. In the past, work has been done to
enable double precision builds of Pd. However,
there is still code in Pd's core which is known to fail with type
double. This page documents alternatives to such
bits of code, and shows test results of double precision Pd,
performance-wise and precision-wise.
So far, I have mainly concentrated on the phase-wrapping classes
which were not yet ready for double precision because they use a
type-specific optimization trick. These classes are: phasor~, cos~,
osc~, vcf~ and tabosc4~. Another known incompatibility is macro
PD_BIGORSMALL in the API
header m_pd.h. Further, I have fixed issues which popped up while
testing mentioned rewritten classes. At the page bottom, you can
download .patch files to implement the code changes in vanilla Pd
0.43-0. A set of tests is included in the .zip. Mind that this is a
work in progress, and issues (hopefully only minor) are still to be
expected.
double precision, why?
The precision of 32 bit floats is equivalent to 24 bit integers,
with the added advantage of a huge range and the associated ease of
programming. So what need is there to build a double
precision Pd? In exceptional cases, 32 bit floats can not properly
express a calculation result, due to rounding. Depending on the
calculation type, this may translate as aliasing in the audio or some
other unexpected effect. There is
always the option to write such calculations in a C external, using
integers for indexing and doubles for running sums and interpolation.
But for me, it is a delight to have double precision directly in a Pd
patch. Pd
is a fast dsp prototyping tool, exactly because you do not need to write things in tedious
low level syntax. Also, for educational purposes it is better to have
calculations in a Pd patch than hidden in a C file. I collected some
examples to illustrate precision bottlenecks in real world dsp
situations.
The first example is where I wanted to produce a 20 seconds
exponential chirp for IR measurement. When this was done as a Pd patch
with regular math objects, my colleague in the IR project perceived a
weird modulation in the high frequency end. A print of time indexes,
expressed in unit seconds, soon pointed to the cause. Numbers were
rounded to their bones. In some math routines, a different order of
operations may help out, but not in the exponential chirp case. The
chirp generator was done as a C external with double precision inside.
The time index sequences below, from regular Pd and my experimental
double precision Pd respectively, illustrate how double precision
numbers have enough 'numerical headroom' for this particular case,
where
the single precision numbers have not.
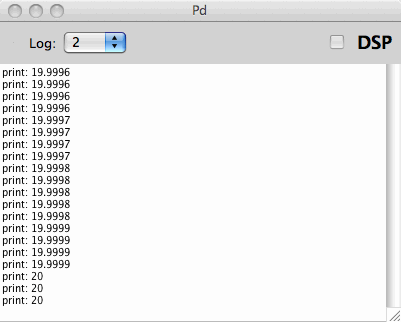
current Pd 0.43
|
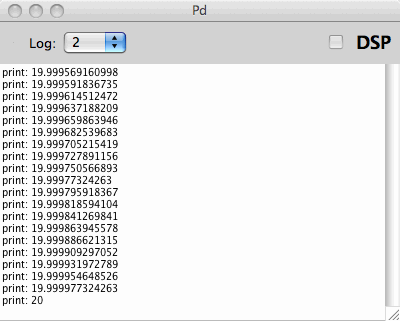
double precision
|
Another, possibly familiar, example is where unit vectors
corresponding to low frequencies are computed.
Cosine tends to be 1., while sine tends to be identical to the angle in
radians. This is caused by rounding. Together these incorrect sine
and cosine still produce a vector with radius ~1. If you use them both,
for example to make an oscillator or resonator, you can go down to
rather low but undefined frequencies. In contrast, doubles have just
enough
bits to represent sine and cosine for LFO frequencies with sufficient
accuracy. Looking at these numbers I guess that doubles would not
be of help in calculating planetary orbits, with their extremely low
frequencies!
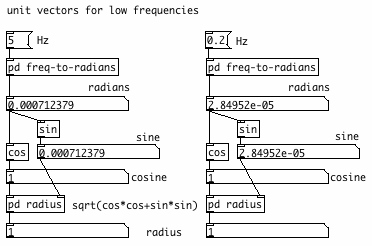
current Pd 0.43
|
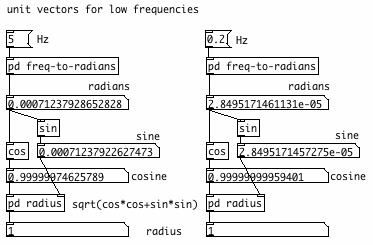
double precision
|
You have probably noticed that single precision floats are
represented in Pd with a maximum of 6 significant digits. This is done
to hide inconsistencies like 33 * 0.3 = 9.900001, which happens when 7
decimal digits are shown. The limitation to 6 significant digits is
however very annoying when we want to type or see large integers, like
indexes of long audio buffers.
In calculations, Pd can use all integers from 0 to
2^24 = 16,777,216, over 16 million. Numbers with up to 8 decimal
digits. But in the GUI, 1 million is shown in scientific notation as
1e+06. This scientific notation also uses a maximum of 6 significant
digits. Therefore, the next representable number is 1.00001e+06, that
is 1 million and 10. See below how the result of 2^20 is rounded in the
GUI, as an example. The fact that numbers are also stored with patches
this way, makes
things worse. At 44100 Hz samplerate, one million samples is about 23
seconds - not at all that much. Longer audio buffers are allowed, but
handling them in the GUI becomes tricky.
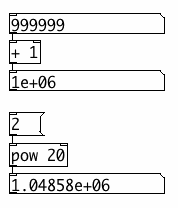
current Pd 0.43
|
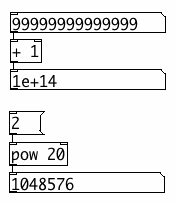
double precision
|
Apart from the representation issue, 32 bit float
resolution leaves little room for interpolation in the case of long
audio buffers. The [soundfiler~] object loads a maximum of 4 million
samples into an array, longer soundfiles are truncated by default (can
be overruled). At 44100 Hz
samplerate, this is about 1.5 minute. The [tabplay4~] object can still
produce a decent sound with that length, provided you do not play at
too low speed.
The table below shows some fractional indexes in double precision
for speed 0.3. In single precision, these numbers can not all be
expressed, and aliasing is the audible result. Double precision
instead, has enough bits to interpolate in buffers of any length your
RAM will permit. Therefore, the maximum buffer length for [soundfiler~]
can be
extended when building Pd for doubles.
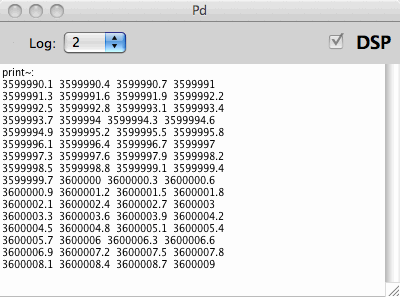
large indexes for fractional speed 0.3, in double precision
|
|
does it sound more beautiful?
The above mentioned examples suggest that double precision is needed
whenever you want to do something eccentric in Pd: very long buffers,
very low frequencies. In such cases it can make a difference for sound
quality indeed.
However, it is certainly not the case that double precision Pd
sounds more beautiful in general. If you listen to [osc~] at any
audible frequency, it is unlikely you'll perceive any difference
between the two precisions. With Fourier analysis, I could not detect
impurities above -100 dB in single precision [osc~]. The object reads
from a 512 point table, with linear interpolation, and this will only
suffer from imprecision at very low subsonic frequencies. The same
observation holds for other table-reading classes, and for the filters.
These classes are designed to function with sufficient precision under
'normal' conditions.
Therefore, it makes no sense to load an arbitrary patch in double
precision Pd and expect to hear better sound. Single precision Pd can
sound very beautiful as well. Problems with sound quality are more
often result of poorly controlled dynamics, than of precision issues or
other deficiencies in Pd objects.
While having limited effect on overall sound quality, double
precision can still be beneficial for the quality of Pd programming in
a different sense. Precision-robustness, combined with full numerical
control from within the GUI, will convert Pd from a pocket calculator
into a scientific calculator. Any user - artist or scientist - could
verify meticulous math stuff directly in Pd, rather than bc, Octave,
Grapher, C, or whatever inconvenient combination of these. As a
computer language, Pd could be used for math classes and assignments at
any level. Abstractions illustrating advanced math topics could be
made. A wider use of Pd as a serious math language could have an impact
on technical knowledge shared within Pd community. In my view, double
precision could affect sound quality in particular via this detour.
benchmarks
The rewritten phase-wrapping classes are optimized as much as possible.
They were profiled individually to make sure none of them suffers
performance loss. This work was done on an Intel Mac, with SSE
instructions automatically generated by the gcc compiler. Later, I
found that Pd compiled for Linux uses the FPU for all floating point
operations, while CPU type is not explicitely defined. I reckoned with
this to make Pd run smooth in both cases.
In order to check overall performance, I searched for pure vanilla
patches, employing a representative mix of objects. The following works
seem suitable for benchmarking: Chaosmonster1 from Martin
Brinkmann, and Cave of Creation
initiated by Hamster on the Pd forum. Both have an emphasis on
vcf~, osc~ and delaylines. As such, they test the modified
phase-wrapping method, the PD_BIGORSMALL definition which is used for
every sample written to a delay line, and speed of memory access for
floats and doubles in general. Since the new code must also perform
well
in a single precision build, comparisons includes three Pd builds:
original = official vanilla Pd 0.43-0
single = vanilla Pd 0.43-0, double-ready modified, but built in single
precision
double = vanilla Pd 0.43-0, double-ready modified, built in double
precision
The benchmarks in table 1 were done in the Shark
profiler application on a MacBook with Intel core2duo 2 GHz.
Numbers represent CPU time as a percentage of total CPU time. Note that
Pd dsp can only use one core at a time. Table 2 represents a Panasonic
Toughbook coreduo 1.83 GHz with Debian Squeeze installed. The results
were read from the top command and are less precise. Top shows
percentages per core by default, and in this case, by lack of Symmetric
Multi-Processing support, that happens to equal the percentage of total
CPU time. Cross-comparisons with figures in table 1 are therefore
irrelevant. Builds with and without SSE instructions are shown in table
2.
|
Cave of Creation (1 instance)
Chaosmonster1 (10 instances)
|
original
12.1
24.0
|
single
10.5
22.0
|
double
10.3
23.6
|
table 1: percentage of total cpu time (+/- 0.1) on MacBook core2duo
2 GHz with OSX 10.5
|
Cave of Creation (1 instance)
Chaosmonster1 (10 instances)
|
original
45 SSE
41.5 FPU
71 SSE
74 FPU
|
single
35.5 SSE
40 FPU
68.5 SSE
70 FPU
|
double
42 SSE
46.5 FPU
72 SSE
74 FPU
|
table 2: percentage of total cpu time (+/- 1) on Panasonic Toughbook
coreduo 1.83 GHz with Debian Squeeze, no SMP support
From this (admittedly small) set of benchmark tests, I conclude that
single precision builds of double-ready Pd may be a tiny bit faster
than current Pd, with SSE more than with FPU instructions. Double
precision Pd is slower than singe precision compiled from the same C
code, but differences are so small that optimizations in the
double-ready code make the net result comparable to current Pd.
More benchmark testing is needed to derive final conclusions. The
rewritten code parts were kind of 'tuned' to the SSE instructions in
the developement process, and modified again when I noticed pathetic
performance on the FPU. Now it is still the question how it behaves on
PPC and ARM.
vectorization of floats and doubles
Expressed in number of bytes, or bits for that matter, double
precision requires two times more data processing than single
precision. How come the performance differences are still so small? It
seems that Pd does not profit from 'vectorization'. On Intel, simple
operations on floating point numbers can be
done in the 128 bit wide xmm registers. Instructions are available to
process two doubles or four floats simultaneously. An example is MOVAPD
- Move Aligned Packed Double-Precision Floating-Point Values. With
proper optimization options set, the compiler will try to implement
such vectorized instructions.
Conditions for compiler autovectorization are rather strict.
Basically, data must be accessible as blocks with a size matching the
corresponding instruction. For many of the SIMD (Single Instruction
Multiple Data) instructions, 16 byte aligned data is required. Pd's
signal block size is set in runtime, and in general the compiler knows
little about data alignment in Pd. Other obstacles for
autovectorization are: potential pointer aliasing, conditional
statements, and loops with too complicated routines. All these
obstacles are frequent in Pd.
When Pd is compiled with gcc flags -ftree-vectorize and
-ftree-vectorizer-verbose=5, the compiler comments indicate that not a
single performance-critical dsp loop in Pd can be autovectorized. Pure
Data operates largely unvectorized. Single precision Pd exploits ~1/4
of the processing capacity in the xmm registers, and double precision
Pd exploits ~1/2 of it. It would be a challenge to modify Pure Data in
a way to profit a bit more from autovectorization, provided this would
not affect functionality, flexibility and portability. But that could
be a major project in itself. The purpose of this digression on
vectorization was to understand the surprisingly small performance loss
of double precision Pd. In terms of CPU load, we pay too much for
single precision, and get double precision at the same price.
double precision and memory space
There seems to be no performance penalty for double precision Pd, but
in terms of memory space the price is of course high. How much audio
can be loaded in 1 gigabyte (1024^3 or 2^30 bytes) of memory? This
would be 2^28 samples for 32 bit float format and 2^27 samples for 64
bit. Assuming 44100 samplerate, this tranlates to about 100 minutes of
single precision audio and 50 minutes of double precision audio.
If Pd is built for double precision, there is no way to make an
exception for audio buffers. Considering the fact that most audio is
stored on disk as 16 bit integers, the sample format conversion to 64
bit floating point seems ridiculous precision overkill, no good for
nothing. Of course, recent computers do have a lot of memory. But in
order to use it all, you may need 64 bit address space, which is yet
another complicated topic.
All wouldn't be so problematic when Pd could load soundfiles in the
background with low priority. At the moment this is not the case. If
you want to play soundfiles in live performance, you need to load all
files into memory before the session, otherwise dropouts will ruin your
show. This annoyance, which is in itself unrelated to the precision
question, asks for a solution anyway.
symbol collision
It is possible to simultaneously run a single precision and a double
precision build of Pd, but they can not be mixed. Function symbols are
identical for both precisions, and fatal symbol collisions can happen
if externals of the wrong type happen to be in Pd's search path, and
loaded accidentally. The different type sizes will definitely lead to a
segmentation fault.
pd-double source code and test patches
Here's the git repository where you can browse and get the double-ready
code:
https://github.com/pd-projects/pd-double
Test patches for pd-double are in this downloadable .zip file:
 pd-double-testpatches.zip, 52 KB
pd-double-testpatches.zip, 52 KB
double precision binary builds
Double precision builds of vanilla Pd are available for OSX and Linux
via this page:
http://puredata.info/downloads/pd-double
Some partly succeeded double precision builds of Pd-extended 0.43.1
are available from the autobuilds:
http://autobuild.puredata.info/auto-build
Windows builds are not yet available because of
double-precision-related bugs in some parts of Windows-specific code.
double precision video demo
I've uploaded a video clip with single/double precision demo here.
The patch used in this video clip is included in the .zip file with
test patches, so you can try the demo if you've built or installed
pd-double.