Helmholtz resonator
time domain pitch tracker for Pure Data
(download at
page bottom)
I'm determined to build a fine vocal pitch shifter one day, which
can also manipulate formants. Reportedly, error-free pitch tracking is
the trickiest aspect, and that's the topic of this page. In a few weeks
of
browsing, coding and finetuning, I had a solid monophonic pitch tracker
built for
Pure Data. The Pd class is named in the honour of the great 19th
century explorer of sound, Hermann von Helmholtz. The guy who listened
through resonators in order to identify frequencies.
Helmholtz resonator |
What a joy it must have been, exploring sound with such
physical means. Nowadays, we're staring at silent computer plots.
Though even this can be exciting for a dsp freak. Well then,
here is the first plot to illustrate my pitch tracker story. It is an
example waveform of a bass clarinet note, from which I want to find the
pitch:
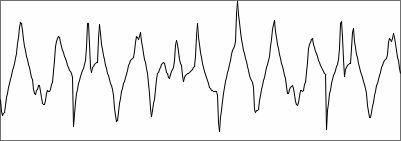 bass clarinet waveform, 1024 samples |
The wave fragment is part of a 1.5 second note, played for the
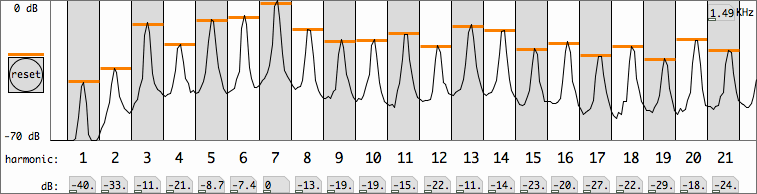
purpose of analysis. Averaging these 1.5 seconds, the partial spectrum
plot below was created. It shows
the first 21 harmonic peaks with their magnitudes in deciBels.
Remarkably, the fundamental is not at all the strongest harmonic. It is
even 40 dB softer than the seventh harmonic, to which the spectrum was
normalized. The orange bars are sliders of a sinusoidal components
synthesizer, and using these I can verify that the fundamental
component does not have a perceivable contribution in the sound. A nice
example of what is called 'missing fundamental'. Yet the pitch is
determined by this fundamental frequency, 68 Hz.
 |
Finding the pitch of a 1.5 second note intentionally played for
analysis is not too difficult. The above plot is from my tool
harmonic_analyser, which does all analysis in frequency domain.
However, analyzing an arbitrary
signal stream live, in small chunks of 1024 samples or so, is a bit
different.
Imagine a chunk where the input is noise only, with a spectrum
showing a lot of peaks and dips. How should it be verified if the peaks
represent harmonics or not? A magnitude threshold could be set, to
start with. Further, peak intervals can be compared to check if there
is
a harmonic ratio. For real time applications, these are not the best
options though.
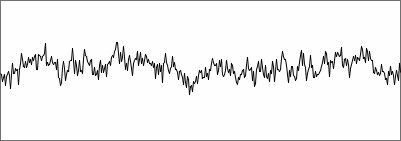 waveform of pink noise, 1024 samples |
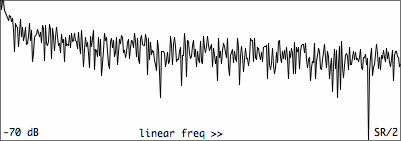 spectrum of the pink noise fragment above |
Alternatively, pitch can be tracked in time domain, as a function of
period length. This redefines the problem: it is now a matter
of finding a repetitive pattern in the waveform. Autocorrelation
transforms a signal segment in such a way that phases line up, and
pattern repetition and length are better recognizable by pronounced
peaks.
Autocorrelation became popular in pitch tracking methods
a few decades ago. Music dsp companies patented their
autocorrelation-based inventions, or even claimed the exclusive right
to use
autocorrelation. See for example this patent
application text.
In the autocorrelation procedure, all samples in a signal segment
are pointwise multiplied with samples of time-shifted versions of the
same signal segment, and summed to create the autocorrelation
coefficients. Autocorrelation can be efficiently done via frequency
domain, where it is a matter of computing the power spectrum. Here is
the mathematical expression of a short time discrete autocorrelation,
as it results from the frequency domain route. x[n] is the signal and
r[k] is the autocorrelation function:
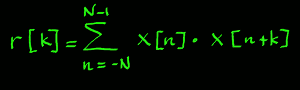 |
At the time shifts where periods in the signal coincide with periods in
the shifted version, autocorrelation coefficients have the largest
value. Here is the bass clarinet fragment once more for an impression:
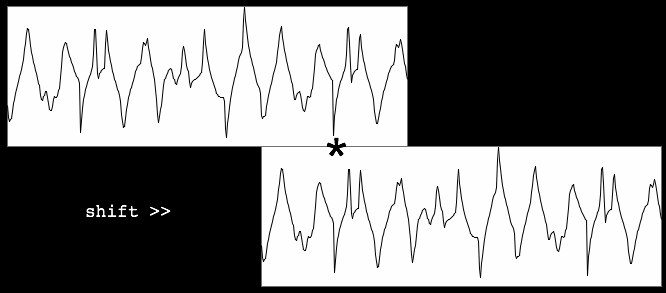 |
From the illustration you may already guess what is the problem with
this method. With increasing shift, the number of samples used to
calculate the autocorrelation decreases, and this influences the output
just as much as the real correlation between the shifted waveforms.
Imagine you
do autocorrelation of the simplest possible waveform, a square or
rectangle. In the output, you get a triangle, just like with
autoconvolution of a square. Any short time autocorrelation is marked
by the triangle effect, regularly called 'bias'.
In the example below, with the bass clarinet fragment as the input,
the triangle effect is clearly observed. The autocorrelation output is
twice as long as the input (minus one sample), just like with
convolution. It is symmetric round the center, and only the right half
is used for analysis. The peak under the red dot is the one that would
indicate a correlation maximum, were it not for the triangle effect.
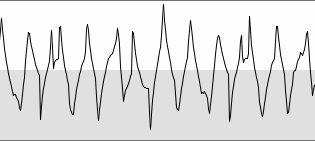 bass clarinet waveform |
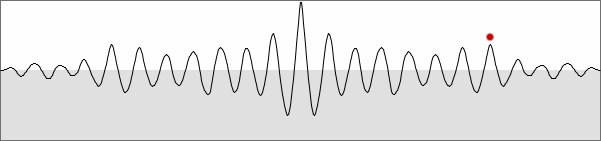 biased autocorrelation of bass clarinet waveform |
In order to undo the triangle effect and raise the correlation
coefficients according to their position, the autocorrelation function
is often 'unbiased'. In effect, that means: divided by the triangle.
Unfortunately, this only works well for the trivial case where the
input is a square wave indeed. Other waveforms are different, and
consequently need different 'unbiasing coefficients'.
The not-exactly-triangle problem discussed above was brilliantly
solved by Philip McLeod, who introduced the Specially Normalized
AutoCorrelation function (SNAC). See his thesis
on pitch detection, which describes the math of SNAC in detail. Instead
of using the triangle for unbiasing, McLeod effectively creates a
modified triangle based on the actual signal values. The modified
triangle could look something like this (right half only):
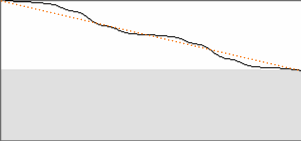 modified triangle for unbiasing |
The shape of the modified triangle is not only dependent on input
frequencies but also on input phases. You may imagine how this
deviation from a triangle will make a difference for the normalized
output. As a result, correlation maxima for a periodic signal will
steadily keep their position, no matter what the input phase.
Further, the modified unbiasing function normalizes the coefficients in a range of -1, 1. Perfectly periodic signals have correlation maxima at value one. Not so perfectly periodic signals have lower maxima, for example when noise is added, or in case of frequency or amplitude changes within the analysis frame. The mathematical formulation of the special normalization can be written:
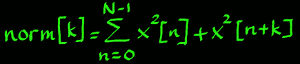 |
Notice that this is for positive k only, the k which are used for
analysis. The Specially Normalized AutoCorrelation is then:
2 * r[k] / norm[k] (recall that r[k] is the biased
autocorrelation)
The values of norm[k] can be efficiently calculated incrementally,
starting from norm[0] = 2. * r[0]. From there, norm[1] = norm[0] - (x2[0]+x2[N-1]).
And so on. This is
integration, or desintegration if you will, as the value becomes
smaller in every iteration. With all the squared signal values
subtracted one by one, it suffers greatly
from numeric imprecision so the norm state must certainly be kept in
double precision.
Specifications of SNAC as presented in McLeod's thesis are
promising. His test results indicate much better accuracy than regular
unbiased autocorrelation, specially for cases with only a few periods
in the analysis frame. McLeod uses SNAC in the Tartini project, a real
time pitch visualization tool for musicians. Would SNAC also be useful
for real time audio processing? The ears are more sensitive
to audio information than the eyes... I implemented the function in a
Pure Data class for evaluation, and did practical tests. Soon I was so
much convinced by SNAC's qualities, that I put a lot of effort in
refining procedures. The evaluation class was renamed [helmholtz~].
Details of this implementation are illustrated below.
Computing the SNAC function is straightforward, following the
formulations in the previous section. Biased autocorrelation is
computed via frequency domain. The FFT size is twice the analysis frame
size to make room for the phase shifts, so the input signal is
zeropadded. No Hann windowing or so is done. Before FFT the signal is
normalized with factor 1. / sqrt(fftsize). The power spectrum is
computed by squaring real and imaginary coefficients and summing these
pointwise. The power spectrum is transformed with IFFT to 'lag domain'
as it is called. It is no longer a signal but a biased autocorrelation,
which is subsequently normalized with the special normalisation to make
the SNAC function. Then it comes to picking the right peak from the
SNAC, the more complicated aspect.
Here's the bass clarinet waveform again, now accompanied with it's
SNAC. The last 15% of the SNAC is ignored because it is too instable.
The modified triangle by which the biased autocorrelation is divided,
may have very small values in that region. The SNAC from the bass
clarinet has an unambiguous maximum indicating the period length
(accentuated by the orange bar).
bass clarinet waveform, 1024 samples |
 SNAC of the bass clarinet waveform |
This was an unproblematic detection. Pitch is calculated with
[samplerate / period length]. It returned the same result as the
frequency domain method, but from a 1024 pt segment instead of 1.5
seconds. Would it always be so straightforward?
Let's do a SNAC of another bass clarinet waveform, with a higher note
this time:
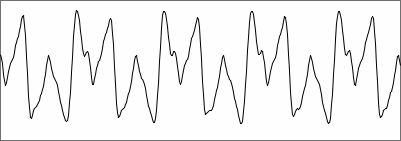 another bass clarinet waveform, 1024 samples |
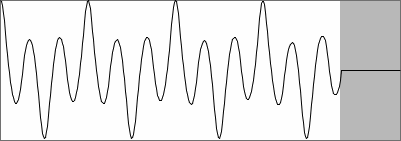 SNAC of the above bass clarinet waveform |
This case shows several maxima of approximately equal height, one
for each period in the frame. Starting the analysis from the left side,
it seems obvious that the first of these maxima should be taken to
represent period length. There's also a few lower peaks inbetween. A
computer doesn't have eyes to overview a dataset - it just comes
accross the peaks one by one. How must it determine if a peak is
relevant or not? From this particular example, it seems that a simple
threshold would do. But in practice, period maxima are not always so
neatly close to value one. They can be lower when there is noise or
modulation in the signal. Moreover, secondary peaks can be much higher
than in this example. False indicators and true indicators can not be
distinguished by a fixed threshold in all cases. Errors are to be
expected every now and then, whatever threshold you set.
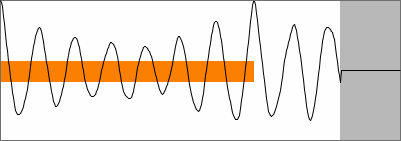
It may seem contradictory, but re-introducing a bit of the triangle
effect helps in finding the representative peak. If all peaks are
weighted by a linear bias function, the period peak can be found as the
'maximum in the frame', instead of the 'first maximum in the frame'.
Assuming that all peaks suffer equally from potential noise or
modulation effects, this peak picking method is insensitive to such
effects.
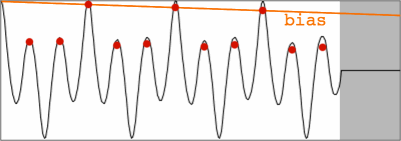 biased (weighted) peak values of SNAC |
Notice that biasing favours not only the first period peak, but even
more so the secondary peaks inbetween. Biasing is thus a matter of
sailing between Scylla and Charibdis - between high and low octave
errors. Here again, no infallible setting can be determined for all
conceivable cases. In practice, I've found that a bias of 0.2 keeps
track even in fairly extreme test conditions. A slightly different
biasing approach can be found in this 1993 article
by Paul Boersma, co-author of the tool Praat (speak, speech).
When high frequency content accumulates in an autocorrelation function,
peaks tend to become narrow, and chances are that an observed local
maximum differs considerably from the real local maximum in the
continuous function represented by the samples. Below is an example of
such a situation. The red dot indicates the maximum value found at
index 5, but the real maximum is a few percent higher.
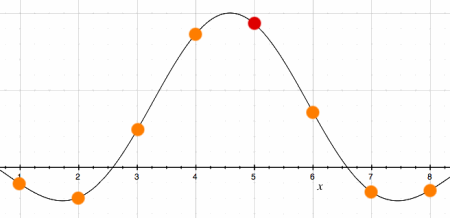 samples of a narrow autocorrelation peak |
Since peak picking is already a delicate matter, it should not be
further complicated by such inaccuracies. Therefore, it is better to
calculate the 'real' maximum of each peak, before comparing them.
'Real' inbetween quotes, because it can only be approximated with more
or less precise methods. An analysis frame may contain lot of peaks,
and the most precise method, sinc interpolation, is not considered here
since it would be too expensive for a real time application.
Parabolic interpolation is an attractive compromise. It needs only
three data points and fits a parabolic curve through these. As the
illustration below indicates, the parabola maximum does not coincide
with the autocorrelation maximum. But it is close enough for a
substantial improvement in peak height accuracy. Using parabolic peak
height correction, the detectable pitch range is extended upwards from
~SR/40 till ~SR/10. As a consequence, procedures can now be done in
downsampled time, thereby increasing their efficiency.
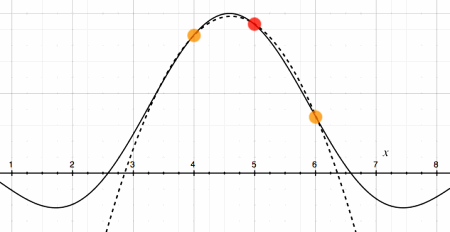 parabola fitted through three autocorrelation samples |
If the values of the three discrete samples are called a, b and c
respectively, the interpolated peak value is calculated:
peakvalue = b + 0.5 * (0.5 * ((c - a) * (c - a))) / (2 * b - a - c)
Once the representative peak is identified, parabolic interpolation
can also be used to calculate period length with better precision, as a
floating point value. Again, the result is not perfect, but precise
enough. Pitch can be found with an accuracy of 0.1 Hz. That is better
than a frequency domain method can do with the same analysis length,
and sufficient for real time audio processing.
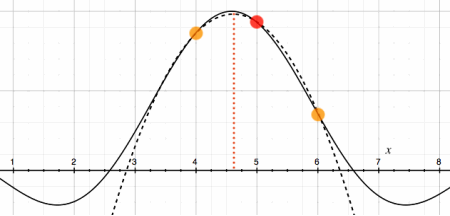 peak index expressed as fractional number |
If the values of the three discrete samples are called a, b and c
respectively, the fractional correction on the integer peak index is
calculated:
fraction = (0.5 * (c - a)) / ( 2. * b - a - c)
The normalized autocorrelation maximum has a double function. Not
only does
it's index indicate period length, but it's height indicates the extent
to which the signal is periodic. I call this the 'fidelity' indicator.
The fidelity indicator tells how much you may believe there really
is a periodic sound with a pitch. Fidelity values can be used to
decide whether a pitch report will be accepted or discarded. Other
people have called it differently, for example Philip McLeod uses
'clarity', and Thomas Baran in his Autotalent plugin uses 'confidence'.
Below is an exaggerated example illustrating fidelity. A sinusoid is
mixed with white noise in a signal-to-noise ratio of 1/1. Pitch is
still found, but with less accuracy, and the autocorrelation maximum,
the fidelity, is about 0.5.
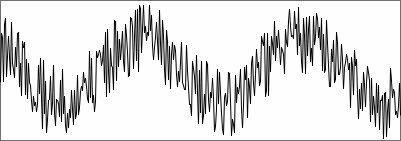 sine mixed with noise in ratio 1/1 |
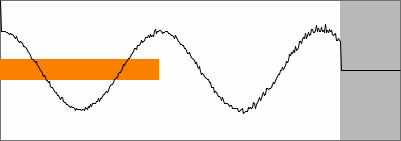 SNAC of the above mix |
If the input is pure white noise, autocorrelation maxima fluctuate
around ~0.2:
 white noise |
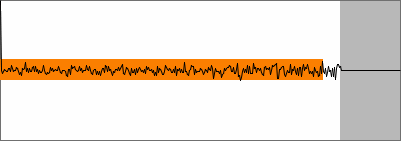 SNAC of white noise |
These examples suggest that a threshold for pitch reporting could be
set at 0.5, to avoid pitch reports for signals which do not really have
a pitch. But this would be too simplistic. Acoustic and and analog
electronic sources do not produce white noise, but pink noise or
brownian noise rather. These types of noise do not have such a
suppressed autocorrelation. By way of test, I SNAC'ed a microphone
input signal without producing any special sound, capturing noise only
from room and preamp. In the plot below, the input noise is of course
heavily magnified to make it visible. The SNAC of the noise input
signal is not so flat at all:
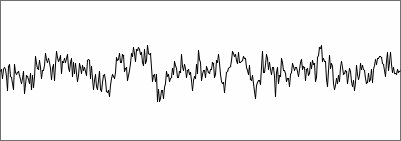 noise from microphone and preamp |
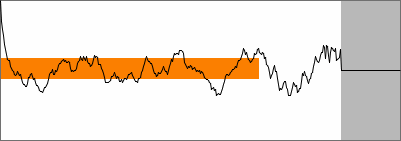 SNAC of microphone noise |
Apart from noise and hum, a lot of other non-periodic or less-periodic
signal types can exist. A sudden frequency jump is the most notable
case. When this happens within an analysis frame, the pitch report is
incorrect, sometimes deviating as much as 20 Hz from one of both input
pitches.
Autocorrelation maxima are lowered in such a case, but they can still
reach values of ~0.85. Below is an example showing a frequency jump of
a
synthesized test signal:
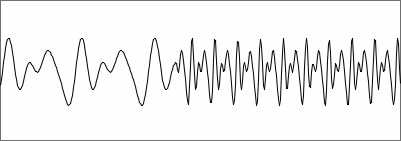 pitch jump in signal, 1024 samples |
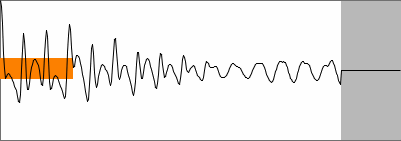 SNAC of the pitch jump |
Pitch jumps are of course common in music and speech. For this
reason the fidelity threshold for pitch reporting must be set fairly
high. Otherwise we get incorrect pitch reports at the onset of each
staccato note. In [helmholtz~] I've set the required fidelity at 0.95
by default. This means, a pitch report is not issued if it's fidelity
is below 0.95. The user can change the required fidelity, even as low
as 0.0, just to see how the SNAC looks with low fidelity, and how
misleading
pitch reports can be.
In the previous section it was illustrated how acoustic / analog
noise can have pretty high maxima in the autocorrelation, as opposed to
white noise. Things become even worse if the input signal is lo-pass
filtered. This makes a dilemma. Filtering
is in itself useful, as it helps avoiding too narrow, pulse-like
autocorrelation peaks, the maximum of which can not be accurately
computed. But if filtering is extreme, the autocorrelation sometimes
breaks through the fidelity threshold during 'silent' passages.
The highest peaks are always on the right side of the SNAC, where the
longest periods and lowest pitches are represented. I was using steep
filters with low cut off frequencies, and
wondered where all the false pitch reports came from. See
the illustrations below, where a sixth order low pass filter with cut
off at
1000 Hz was used.
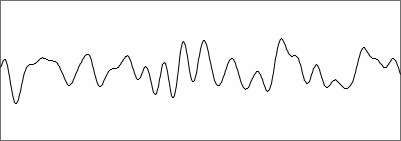 microphone noise filtered at 1000 Hz |
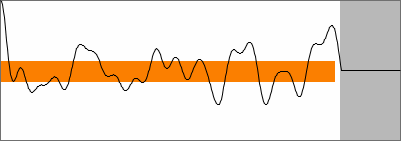 SNAC of filtered microphone noise |
It would be possible to set a noise gate before the analysis, but I
also observed that adding a tiny bit of white noise after the filter reduced the
colored
noise peaks to a safe level, while it does not degrade the accuracy of
period analysis.
This observation gave rise to a nice solution. Initially, I was
looking for the perfect white noise generator. Then it occured to me
that a simple pulse, one per analysis frame, would be the best
equivalent for perfect white noise. This pulse could be inserted in the
signal. But even better is to implement it in the autocorrelation
function directly, as a 'perfect white noise equivalent floor'.
This means no more than setting a minimum value for r[0], before
normalization. The minimum r[0] value is calculated from a desired
minimum white noise equivalent,
expressed in RMS amplitude. If we call the white noise equivalent WNEmin,
the mathematical expression for the minimum r[0] is:
r[0]min = (WNEmin / sqrt(1./framesize)^2
The artificial white noise floor compensates the low frequency bias of the input noise, and is much more effective than a straightforward noise gate. Below is a SNAC from filtered microphone noise, now with an artificial noise floor set at RMS 0.001 or -60 dB. The level is user-settable in [helmholtz~] as a sensitivity parameter, so it can be tuned to the noisiness of hardware or environment.
 SNAC of filtered microphone noise, WNEmin = 0.001 |
I've produced quite some test patches for [helmholtz~], and they are
included in the package with source and binaries. Here is a summary of
my observations.
Accuracy is within +/- 0.1 Hz for stationary signals, so accuracy is
not a point of concern. Harder to verify and quantify is the balance
between robustness and responsiveness. False pitch reports are to be
avoided, but I do not want to miss relevant reports, otherwise a
processed or synthesized pitch will be marked by discontinuities.
As illustrated in the previous section, a sudden frequency jump
should result in a report dropout, or in the case of overlapping
analyses, a few report dropouts. That is inevitable. But how does
[helmholtz~] behave in the case of continuous frequency modulation,
that is, vibrato? A vibrato speed around 20 Hz starts to cause report
dropouts when vibrato depth is more than ~1/8 of the pitch. Such
vibrato speed and depth is not likely to happen in real instruments.
Moderate vibrato is no problem.
Signal level jumps over 20 dB or more cause a pitch report dropout.
How about sinusoidal amplitude modulation, that is, tremolo? At a
modulation depth of 10 dB, report dropouts start to happen when
modulation speed approaches 20 Hz. Again, such modulation is more than
can be expected from most instruments or voice. But I could think of a
case: the samba flute. Indeed, [helmholtz~] can not find my samba
flute's pitch, unless fidelity threshold is lowered to 0.9. This is too
low for robustness.
How much noise can be mixed to a periodic signal before [helmholtz~]
loses track of the pitch? It depends on the noise type. Pink noise is
used for the test to simulate a realistic situation. In general, a S/N
ratio smaller than 15 dB becomes problematic. Not so much because of
pitch inaccuracy, but because of pitch report dropout.
[helmholtz~] can find only one pitch at a time, it is not suitable
for polyphonic material. What happens if two pitches sound
simultaneously nonetheless? It depends. If one instrument plays a tonic
and another plays the fifth, [helmholtz~] perceives the tonic as second
harmonic and the fifth as third harmonic. Reported pitch is one octave
below the tonic, because that is the period of the combination. If two
pitches are meant to be the same, but out of tune (up to 50
cents or so), and equally loud, [helmholtz~] gives the average pitch.
Apparently, it perceives the mix as one pitch with amplitude
modulation.
In many other cases of inharmonic relations, [helmholtz~] will just
give no pitch report at all.
Summarizing, pitch reports are missing in case of sudden frequency
or level jumps, fast modulation, too low periodicity/noise ratio, and
inharmonic sounds. Moderate
modulations are of no concern. In the case of frequency jumps, I
prefer report dropout over an incorrect report, because deviation can
be large. But in the case of noise, pitch inaccuracy is not too bad,
and I would prefer inaccuracy over report dropouts. Unfortunately,
autocorrelation
can not by itself distinguish between noise and frequency jumps. But we
have the signal and spectrum too. A lot more information can be
extracted, to help in decision making. That is for future updates, or
maybe for a new class.
Latency of pitch tracking is determined by analysis frame size,
and detected pitch reflects the average in the frame. Report dropouts
can add to the latency. If a note starts halfway an analysis frame, the
pitch report is unreliable and therefore discarded. This means, you get
the pitch report one and a half frames after the note started.
Overlapping analyses will reduce this extra latency. Four times
overlap is practical.
No matter what overlap, a full frame size is
the minimum latency. It is considerable, as size must always be
tailored to the lowest pitch
expected in the sound material. [helmholtz~] needs at least 1.2 times
the period length for proper analysis. With frame size 1024 and
samplerate 44100, pitch from 50 Hz upwards can be detected. This is a
useful setting for many instruments. Bass instruments need 2048
samples, and a female voice can do with 512.
Processing latency is nowhere better perceived than at the onset of
a sound. It is a pity that the largest analysis latency happens exactly
at the onset of a new note. Specially if the new note is of high pitch.
It may be the case that a dozen periods are past before a pitch report
is finally delivered. Would it be possible to have shorter analysis
frames running in parallel, and detect high pitches earlier? That is
tricky, because a short SNAC can easily misinterpret a higher
harmonic as the fundamental. In such cases, information about the
signal's instantaneous power might help out, but this is still very
experimental and I've not implemented it in [helmholtz~] (see page IPPASS).
Since autocorrelation can be done via frequency domain, it is
relatively efficient. Where it would be an order N * N operation in
time domain, like convolution, it is an order N * log(N) operation with
FFT, like fast convolution. The Special Normalization of SNAC requires
division, which is a few times more expensive than multiplication.
Further, parabolic interpolation is used, but only for coefficients
which are local peaks. [helmholtz~] is not fully optimized, as it
computes the full SNAC function for plotting. This has been very useful
for research, and I will leave it like this.
Better efficiency can be achieved by operating in downsampled time.
To find pitches up to 1000 Hz, samplerate 11025 is sufficient. That
means resampling factor 0.25, or one in four samples of a signal
sampled at 44100 Hz.
At samplerate 44100, [helmholtz~] does ~0.6% CPU load on my 2 GHz
computer, with default settings (no overlap). At samplerate 11025 it
does ~0.16% CPU load. In practice, I would do 2 or 4 times overlap to
get a smoother message stream. Filtering is recommended at default
samplerate, and of course obligatory for downsampled rate.
Of course, all test results would be meaningless if [helmholtz~]
doesn't please the ear. It's ultimate task is to control pitch for
processing and synthesis purposes, and it must do so without glitches.
In particular, it should excel in tracking voice, so the procedure can
be built in a pitch- and formant manipulator some day.
I connected a simple sine oscillator to the pitch message output
from [helmholtz~]. During development, I constantly monitored the
translation from voice to sinewave. That was how I could identify
errors which were not so obvious from plots or numboxes. Without these
checks, I might not have traced the colored-noise-problem for example.
Probably, [helmholtz~] is somewhat biased towards my voice now. It
doesn't make mistakes any more with this source. Instead, I am the one
who is at fault: [helmholtz~] has learnt me that my voice crackles a
lot. When crackling, the pitch drops by an octave. I was never aware of
that. I produced a one-second raspy note for harmonic_analyser to see
if it's true, and yes, it agrees with [helmholtz~]: one octave down!
This peculiarity was easily solved with a pd patch 'if below 100 Hz,
multiply by two'. General rules can not be made for all possible
defects in a human voice or an instrument.
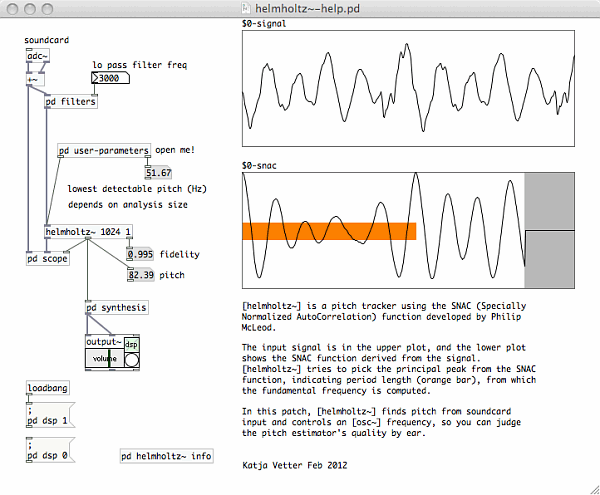 help patch for [helmholtz~], here with SNAC of my crackling voice |
If you want to check [helmholtz~] for your own purposes, download
the
package with source code, binaries for 32 bit OSX, Linux and Windows,
help- and test patches. It was developed and built against Pd-extended
0.42.5. Get Pd-extended from http://puredata.info.
 helmholtz~.zip:
source, binaries and patches, 116 KB helmholtz~.zip:
source, binaries and patches, 116 KB |